My apologies for not responding sooner. I was dealing with other projects and I had to put this on the back burner.
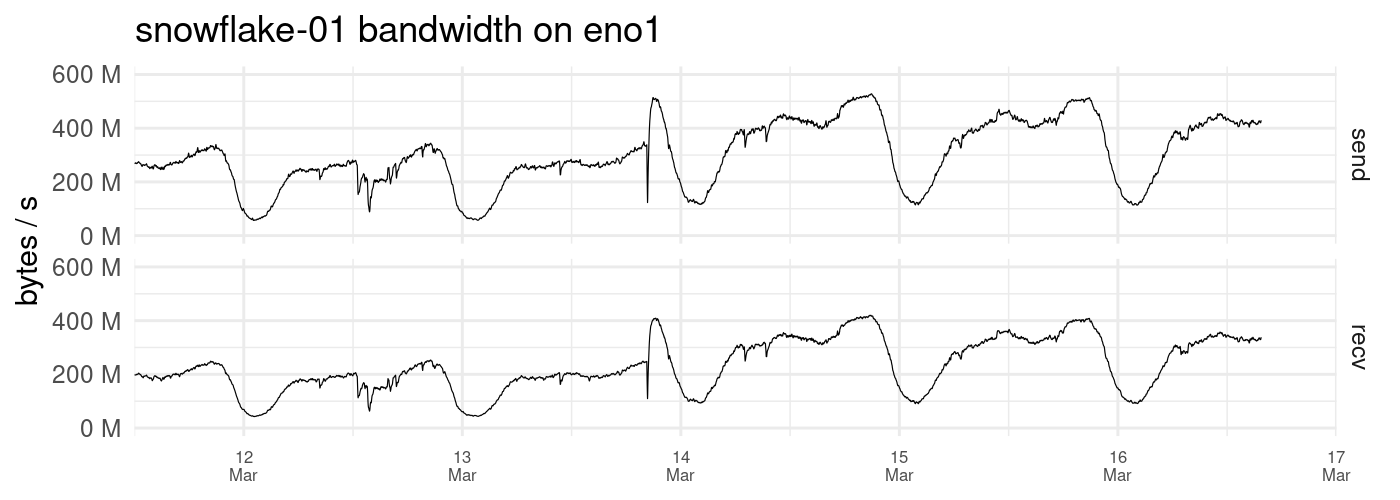
To give you an update and also to give you a more accurate picture of my setup, I’m running my snowflakes on a bare metal and under several VMs. Each virtual machine has its own IP address and operating system and runs 5 docker containers / snowflake proxies. I must also admit that my network does have unusually good connectivity and attracts a lot of Iranian users who may not be able to connect to other setups as you will see in my logs later in this post. Currently each 5 container setup relays just about as much traffic as a Tor relay with Max Advertised bandwidth of 15 MiB which is cool.
I’m sure the memory leak is there which means the memory usage goes up when the activities are high, which is understandable, but the memory doesn’t fully recover when things cool down. This leads to the eventual OOM crash.
The good part is that the whole VM doesn’t crash. Only the containers and they do so one at a time, couple of hours apart so the rest of them keep on relaying. and the ones that crash, restart by themselves immediately and keep going. This is only noticeable if you’re monitoring the memory as it partially drops when one of the containers restart. You can also notice this in the log which only indicates the restart with no other clue. Aside from that, there are no error messages in the docker logs. You can only see an indication of oom kill and disconnected shim in the system logs :
Mar 21 10:29:59 vpn kernel: oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=f5dec5eb8a4034e22bbc3a5eb2b038e918f645d786d9de614375e13635bf7fe5,mems_allowed=0,global_oom,task_memcg=/docker/039c643a0198f2d378c3515538d053a38873408b526cc3134923b9b07f8ef971,task=proxy,pid=8477,uid=1000
Mar 21 10:29:59 vpn kernel: Out of memory: Killed process 8477 (proxy) total-vm:2375972kB, anon-rss:904156kB, file-rss:1720kB, shmem-rss:0kB, UID:1000 pgtables:3448kB oom_score_adj:0
Mar 21 10:29:59 vpn containerd[853]: time="2023-03-21T10:29:59.599814434Z" level=info msg="shim disconnected" id=039c643a0198f2d378c3515538d053a38873408b526cc3134923b9b07f8ef971
Mar 21 10:29:59 vpn containerd[853]: time="2023-03-21T10:29:59.603234663Z" level=warning msg="cleaning up after shim disconnected" id=039c643a0198f2d378c3515538d053a38873408b526cc3134923b9b07f8ef971 namespace=moby
Mar 21 10:29:59 vpn containerd[853]: time="2023-03-21T10:29:59.603479972Z" level=info msg="cleaning up dead shim"
Mar 21 10:29:59 vpn dockerd[1185]: time="2023-03-21T10:29:59.602807645Z" level=info msg="ignoring event" container=039c643a0198f2d378c3515538d053a38873408b526cc3134923b9b07f8ef971 module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
Mar 21 10:29:59 vpn containerd[853]: time="2023-03-21T10:29:59.626274657Z" level=warning msg="cleanup warnings time=\"2023-03-21T10:29:59Z\" level=info msg=\"starting signal loop\" namespace=moby pid=9028 runtime=io.containerd.runc.v2\n"
Mar 21 10:29:59 vpn systemd[1]: var-lib-docker-overlay2-8a4cc8ea209ea49b8d28e7d573968499aa122988853a6ea0eca9450758c7bb2a-merged.mount: Succeeded.
Mar 21 10:29:59 vpn containerd[853]: time="2023-03-21T10:29:59.919039358Z" level=info msg="loading plugin \"io.containerd.event.v1.publisher\"..." runtime=io.containerd.runc.v2 type=io.containerd.event.v1
Mar 21 10:29:59 vpn containerd[853]: time="2023-03-21T10:29:59.919108918Z" level=info msg="loading plugin \"io.containerd.internal.v1.shutdown\"..." runtime=io.containerd.runc.v2 type=io.containerd.internal.v1
Mar 21 10:29:59 vpn containerd[853]: time="2023-03-21T10:29:59.919125321Z" level=info msg="loading plugin \"io.containerd.ttrpc.v1.task\"..." runtime=io.containerd.runc.v2 type=io.containerd.ttrpc.v1
Mar 21 10:29:59 vpn containerd[853]: time="2023-03-21T10:29:59.919381751Z" level=info msg="starting signal loop" namespace=moby path=/run/containerd/io.containerd.runtime.v2.task/moby/039c643a0198f2d378c3515538d053a38873408b526cc3134923b9b07f8ef971 pid=9048 runtime=io.containerd.runc.v2
And to get a better picture of the kind of connections, this is the log for one of the containers out of 5 on one of the VMs:
2023/03/23 05:29:32 Proxy starting
2023/03/23 05:29:39 NAT type: unrestricted
2023/03/23 06:29:32 In the last 1h0m0s, there were 151 connections. Traffic Relayed ↑ 1672090 KB, ↓ 201928 KB.
2023/03/23 07:29:32 In the last 1h0m0s, there were 184 connections. Traffic Relayed ↑ 3237160 KB, ↓ 397758 KB.
2023/03/23 08:29:32 In the last 1h0m0s, there were 220 connections. Traffic Relayed ↑ 4426205 KB, ↓ 577664 KB.
2023/03/23 09:29:32 In the last 1h0m0s, there were 240 connections. Traffic Relayed ↑ 6414385 KB, ↓ 925416 KB.
2023/03/23 10:29:32 In the last 1h0m0s, there were 245 connections. Traffic Relayed ↑ 5536270 KB, ↓ 832924 KB.
2023/03/23 11:29:32 In the last 1h0m0s, there were 256 connections. Traffic Relayed ↑ 3594474 KB, ↓ 618120 KB.
2023/03/23 12:29:32 In the last 1h0m0s, there were 239 connections. Traffic Relayed ↑ 4400832 KB, ↓ 631875 KB.
2023/03/23 13:29:32 In the last 1h0m0s, there were 255 connections. Traffic Relayed ↑ 6612566 KB, ↓ 792439 KB.
2023/03/23 14:29:32 In the last 1h0m0s, there were 259 connections. Traffic Relayed ↑ 6693017 KB, ↓ 767227 KB.
2023/03/23 15:29:32 In the last 1h0m0s, there were 288 connections. Traffic Relayed ↑ 9075662 KB, ↓ 1082406 KB.
2023/03/23 16:29:32 In the last 1h0m0s, there were 305 connections. Traffic Relayed ↑ 11216653 KB, ↓ 1283160 KB.
The last line shows over 11 GB of data transfer in one hour. And this is a snapshot of the current unique IP addresses with ASSURED UDP status in my conntrack table and where they’re coming from:
1 Chile
2 China
1 Ecuador
1 Finland
2 France
4 Germany
576 Iran
1 Italy
1 Japan
1 Lithuania
1 Netherlands
6 Russia
1 Ukraine
3 United States
It was also suggested that I should reduce the number of connections to see how that works. Here’s an example of another container:
2023/03/23 10:16:09 Proxy starting
2023/03/23 10:16:21 NAT type: unrestricted
2023/03/23 11:16:09 In the last 1h0m0s, there were 32 connections. Traffic Relayed ↑ 266465 KB, ↓ 45634 KB.
2023/03/23 12:16:09 In the last 1h0m0s, there were 34 connections. Traffic Relayed ↑ 890410 KB, ↓ 92998 KB.
2023/03/23 13:16:09 In the last 1h0m0s, there were 55 connections. Traffic Relayed ↑ 701485 KB, ↓ 80086 KB.
2023/03/23 14:16:09 In the last 1h0m0s, there were 67 connections. Traffic Relayed ↑ 1369366 KB, ↓ 186713 KB.
2023/03/23 15:16:09 In the last 1h0m0s, there were 50 connections. Traffic Relayed ↑ 1402332 KB, ↓ 175346 KB.
2023/03/23 16:16:09 In the last 1h0m0s, there were 48 connections. Traffic Relayed ↑ 455562 KB, ↓ 74556 KB.
2023/03/23 17:16:09 In the last 1h0m0s, there were 56 connections. Traffic Relayed ↑ 1100026 KB, ↓ 163992 KB.
And the conntrack:
1 Canada
1 China
2 Finland
2 Germany
30 Iran
1 Mexico
6 Russia
1 Ukraine
6 United States
I’m afraid the problem is still there. The crashes may happen less frequently but they do happen
nevertheless.
Cheers.