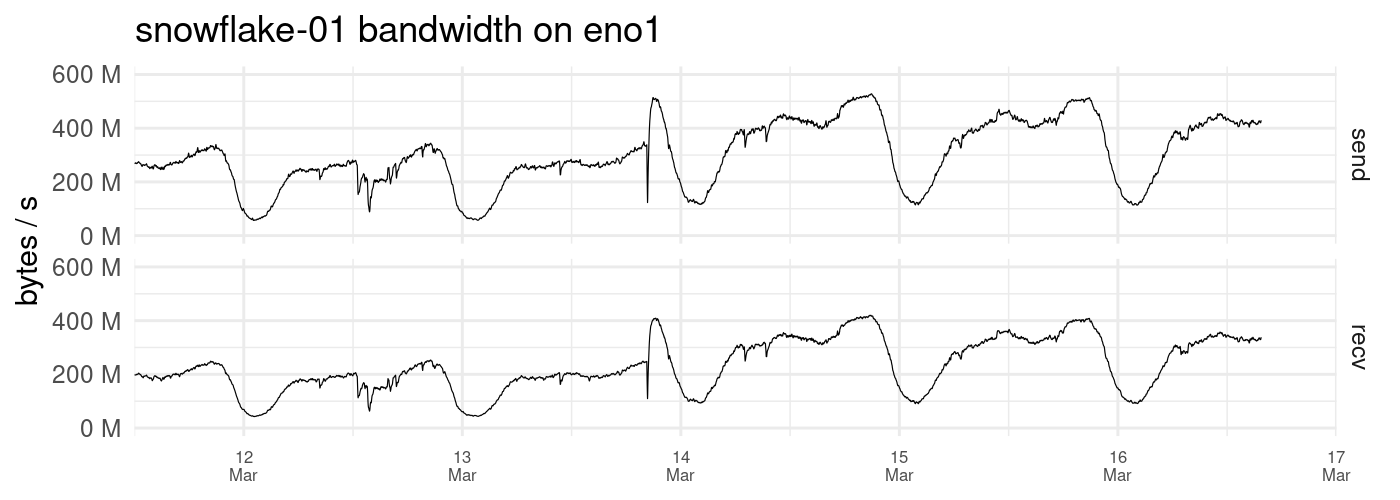
I hate to flood the forum with log files but I’m going to post a fraction of what I get in the log to show what’s happening.
runtime stack:
runtime.throw({0x927582?, 0x400000?})
/usr/local/go/src/runtime/panic.go:992 +0x71
runtime.sysMap(0xc046000000, 0x40b969?, 0xc00003e548?)
/usr/local/go/src/runtime/mem_linux.go:189 +0x11b
runtime.(*mheap).grow(0xcc7a00, 0xc00003e400?)
/usr/local/go/src/runtime/mheap.go:1413 +0x225
runtime.(*mheap).allocSpan(0xcc7a00, 0x1, 0x0, 0x11)
/usr/local/go/src/runtime/mheap.go:1178 +0x171
runtime.(*mheap).alloc.func1()
/usr/local/go/src/runtime/mheap.go:920 +0x65
runtime.systemstack()
/usr/local/go/src/runtime/asm_amd64.s:469 +0x49
goroutine 194426 [running]:
runtime.systemstack_switch()
/usr/local/go/src/runtime/asm_amd64.s:436 fp=0xc001d7bbd0 sp=0xc001d7bbc8 pc=0x460d60
runtime.(*mheap).alloc(0x0?, 0xc001d7bd30?, 0x80?)
/usr/local/go/src/runtime/mheap.go:914 +0x65 fp=0xc001d7bc18 sp=0xc001d7bbd0 pc=0x426705
runtime.(*mcentral).grow(0x2000?)
/usr/local/go/src/runtime/mcentral.go:244 +0x5b fp=0xc001d7bc60 sp=0xc001d7bc18 pc=0x41751b
runtime.(*mcentral).cacheSpan(0xcd8900)
/usr/local/go/src/runtime/mcentral.go:164 +0x30f fp=0xc001d7bcb8 sp=0xc001d7bc60 pc=0x41734f
runtime.(*mcache).refill(0x7f2baac835b8, 0x11)
/usr/local/go/src/runtime/mcache.go:162 +0xaf fp=0xc001d7bcf0 sp=0xc001d7bcb8 pc=0x4169cf
runtime.(*mcache).nextFree(0x7f2baac835b8, 0x11)
/usr/local/go/src/runtime/malloc.go:886 +0x85 fp=0xc001d7bd38 sp=0xc001d7bcf0 pc=0x40ca65
runtime.mallocgc(0x60, 0x0, 0x1)
/usr/local/go/src/runtime/malloc.go:1085 +0x4e5 fp=0xc001d7bdb0 sp=0xc001d7bd38 pc=0x40d0e5
runtime.makechan(0x0?, 0x0)
/usr/local/go/src/runtime/chan.go:96 +0x11d fp=0xc001d7bdf0 sp=0xc001d7bdb0 pc=0x40563d
github.com/pion/sctp.(*ackTimer).start(0xc00143ca80)
/go/pkg/mod/github.com/pion/sctp@v1.8.2/ack_timer.go:51 +0x9f fp=0xc001d7be40 sp=0xc001d7bdf0 pc=0x6c785f
github.com/pion/sctp.(*Association).handleChunkEnd(0xc000b16a80)
/go/pkg/mod/github.com/pion/sctp@v1.8.2/association.go:2238 +0x9e fp=0xc001d7be80 sp=0xc001d7be40 pc=0x6d673e
github.com/pion/sctp.(*Association).handleInbound(0xc000b16a80, {0xc03c7f3700?, 0x2000?, 0xc001b7ff70?})
/go/pkg/mod/github.com/pion/sctp@v1.8.2/association.go:608 +0x2ea fp=0xc001d7bf28 sp=0xc001d7be80 pc=0x6cb54a
github.com/pion/sctp.(*Association).readLoop(0xc000b16a80)
/go/pkg/mod/github.com/pion/sctp@v1.8.2/association.go:521 +0x1cd fp=0xc001d7bfc8 sp=0xc001d7bf28 pc=0x6ca1ed
github.com/pion/sctp.(*Association).init.func2()
/go/pkg/mod/github.com/pion/sctp@v1.8.2/association.go:339 +0x26 fp=0xc001d7bfe0 sp=0xc001d7bfc8 pc=0x6c9006
runtime.goexit()
/usr/local/go/src/runtime/asm_amd64.s:1571 +0x1 fp=0xc001d7bfe8 sp=0xc001d7bfe0 pc=0x462e41
created by github.com/pion/sctp.(*Association).init
/go/pkg/mod/github.com/pion/sctp@v1.8.2/association.go:339 +0xd0
goroutine 107 [IO wait]:
internal/poll.runtime_pollWait(0x7f2b84015f68, 0x72)
/usr/local/go/src/runtime/netpoll.go:302 +0x89
internal/poll.(*pollDesc).wait(0xc0001da480?, 0xc00024c000?, 0x0)
/usr/local/go/src/internal/poll/fd_poll_runtime.go:83 +0x32
internal/poll.(*pollDesc).waitRead(...)
/usr/local/go/src/internal/poll/fd_poll_runtime.go:88
internal/poll.(*FD).Read(0xc0001da480, {0xc00024c000, 0x13d6, 0x13d6})
/usr/local/go/src/internal/poll/fd_unix.go:167 +0x25a
net.(*netFD).Read(0xc0001da480, {0xc00024c000?, 0xc00028b820?, 0xc00024c02a?})
/usr/local/go/src/net/fd_posix.go:55 +0x29
net.(*conn).Read(0xc000112108, {0xc00024c000?, 0x1ffffffffffffff?, 0x39?})
/usr/local/go/src/net/net.go:183 +0x45
crypto/tls.(*atLeastReader).Read(0xc04416ca08, {0xc00024c000?, 0x0?, 0x8?})
/usr/local/go/src/crypto/tls/conn.go:785 +0x3d
bytes.(*Buffer).ReadFrom(0xc000155078, {0x9daf60, 0xc04416ca08})
/usr/local/go/src/bytes/buffer.go:204 +0x98
crypto/tls.(*Conn).readFromUntil(0xc000154e00, {0x9db920?, 0xc000112108}, 0x13b1?)
/usr/local/go/src/crypto/tls/conn.go:807 +0xe5
crypto/tls.(*Conn).readRecordOrCCS(0xc000154e00, 0x0)
/usr/local/go/src/crypto/tls/conn.go:614 +0x116
crypto/tls.(*Conn).readRecord(...)
/usr/local/go/src/crypto/tls/conn.go:582
crypto/tls.(*Conn).Read(0xc000154e00, {0xc0002c2000, 0x1000, 0x7f0360?})
/usr/local/go/src/crypto/tls/conn.go:1285 +0x16f
bufio.(*Reader).Read(0xc0001b3c80, {0xc0001244a0, 0x9, 0x7fe722?})
/usr/local/go/src/bufio/bufio.go:236 +0x1b4
io.ReadAtLeast({0x9dae00, 0xc0001b3c80}, {0xc0001244a0, 0x9, 0x9}, 0x9)
/usr/local/go/src/io/io.go:331 +0x9a
io.ReadFull(...)
/usr/local/go/src/io/io.go:350
net/http.http2readFrameHeader({0xc0001244a0?, 0x9?, 0xc0442860f0?}, {0x9dae00?, 0xc0001b3c80?})
/usr/local/go/src/net/http/h2_bundle.go:1566 +0x6e
net/http.(*http2Framer).ReadFrame(0xc000124460)
/usr/local/go/src/net/http/h2_bundle.go:1830 +0x95
net/http.(*http2clientConnReadLoop).run(0xc00004bf98)
/usr/local/go/src/net/http/h2_bundle.go:8819 +0x130
net/http.(*http2ClientConn).readLoop(0xc00024a300)
/usr/local/go/src/net/http/h2_bundle.go:8715 +0x6f
created by net/http.(*http2Transport).newClientConn
/usr/local/go/src/net/http/h2_bundle.go:7443 +0xa65
~~~
This goes on for pages and pages in the log.